Uplift Modeling for Multiple Treatments with Cost Optimization, Zhao et. al., arXiv, 2019
TLDR; Meta-Learning is an effective method to optimise and personalise delivery of designs, content, products, campaigns or messages for maximal uplift and value. The paper introduces the notion of Net Value Conditional Average Treatment Effect (Net Value CATE), shows how to estimate it using meta-learning and outlines the system design in place at Uber to provide causal uplift models at scale.
After having covered Online Auctions for the last six weeks, it is time to shift gears and look at some recent measurement and machine learning papers. Before we start, a big thanks to all readers of the brief who provided feedback over the last weeks! Please continue doing so to help us improve the brief. Every single point will be considered and acted upon – promise! You can reach out for example by sending an e-mail to ben@thebrief.blog. As a result of your input, notification e-mail for new posts now always contain the full post so you don’t have to go to the website. Also, we strive for making the briefs easier to read by including more visual content, such as graphs and tables. Finally, from now on there will always be a TLDR section covering the main message of the paper at the top. If you find the research summaries useful, please share with your friends and colleagues!
We start the measurement and machine learning weeks with an interesting piece by folks at Uber around uplift modelling in case of multiple treatments with potentially heterogeneous costs.
Suppose you plan to deliver a message to your users to optimise for some outcome – such as a conversion – and you can send the message through various channels, such as e-mail, push notification, onsite campaign or else. Delivering a message is costly and different users respond differently on different channels. The paper tackles the question of how to select the optimal channel for each user for optimal causally estimated uplift and generally applies to any decision-making context with multiple heterogeneous cost treatments.
Uplift modeling can be used to estimate which users are likely
to benefit from a treatment and then prioritize delivering or
promoting the preferred experience to those users. An important
but so far neglected use case for uplift modeling is an experiment
with multiple treatment groups that have different costs, such
as for example when different communication channels and
promotion types are tested simultaneously.
Meta-Learners for measuring uplift in the Neyman-Rubin framework
The paper is all about personalisation and tackles the problem from a causal inference perspective, using the Neyman-Rubin framework. In particular, the estimand of interest is the conditional average treatment effect (CATE), defined as the average treatment effect conditional on user observables.
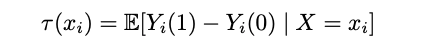
The above equation expresses CATE, where tau(x_i) is CATE for users with observables x_i and Y_i(1) is the potential outcome for user i if she receives the treatment and Y_i(0) if she doesn’t.
The CATE is of special interest to researchers because it allows them to understand how treatment effects vary depending on the observed characteristics of the population of interest. (…) Uplift modeling can be seen as the task of using machine learning approaches to estimate the CATE.
Given we defined what we are interested in, how do we go about flexibly estimating the CATE? The paper explores various meta-learners for doing so. These learners usually contain multiple stages that are ultimately combined. One of the simplest meta-learners is the two-model approach. The two model approach estimator
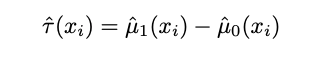
estimates CATE by fitting the conditional mean for treatment – the first term on the right hand side – and control group – second term on the right hand side – independently and then combines them. An advantage of this approach that basically any suitable model can be used for the conditional means. The same holds for more sophisticated estimators evaluated in the paper, known as X-learner and R-learner, which both use a propensity score.
The Net Value CATE – Extending the learners to multiple treatment groups and different costs
Extending the learners to multiple treatments is done by estimating the conditional mean and the propensity score – both are needed in the X- and R-learner – for all available treatments. More specifically, the conditional mean for treatment t_j is

and the propensity score is

Again, any suitable model can be use for estimating those quantities .
To incorporate costs, the paper introduces the interesting and relevant notion of Net Value Optimisation, quantified as Net Value CATE:
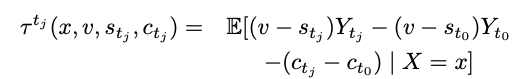
In the Net Value CATE, v reflects the value of a conversion, which is by assumption homogenous across treatments. s reflects what the authors term triggered cost for a conversion, which can differ for each treatment and user. This could, for example, reflect the discount value of a promotion that might differ across promotions (treatments). Importantly, it is only paid upon conversion. Finally, c reflects the impression costs per user, which can again differ across treatments and users and is independent of conversion. As before, Y is the conversion propensity.
Evaluating the Performance of Meta-Learners for the Net Value CATE
There is generally no straightforward way for evaluating learning performance in causal inference problems using cross validation, as the counterfactual outcome is fundamentally unobservable and hence there is no ground truth. Following the discussion in this literature, the authors use the Area Under the Uplift Curve (AUCC) as an evaluation metric and apply the learners to both synthetic and real world data to assess performance.
This metric is calculated by sorting the observations in the testing set to 100 bins from the highest predicted uplift to the lowest. Because the treatment assignment is randomized, we have an approximately equal amount of treatment and control observation in each bin, which allows us to calculate the average treatment effect within each bin. We then calculate the average difference between the treatment and the control if only the highest p bins in the treatment are treated with the treatment condition. The best performing method according to this criterion is the one with the largest AUUC.
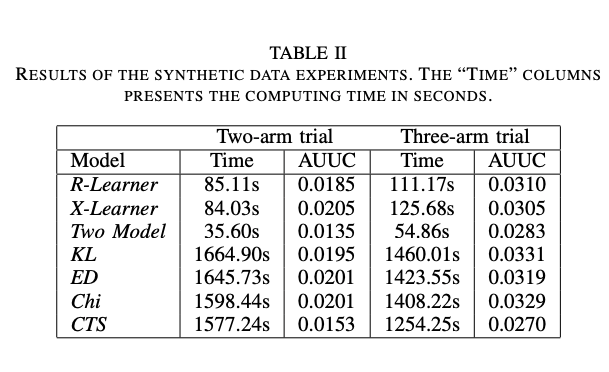
Table II shows the X-learner has the highest AUUC and is still computable in a reasonable time. The comparison is not only made between different meta-learners, but also includes decision-tree based methods using the Kullback-Leibler divergence (KL), the Euclidean distance (EL), the chi-squared divergence (Chi) and a contextual treatment selection (CTS) algorithm.
The uplift curve and the application of the algorithms to the conversion optimisation task confirm the above result.

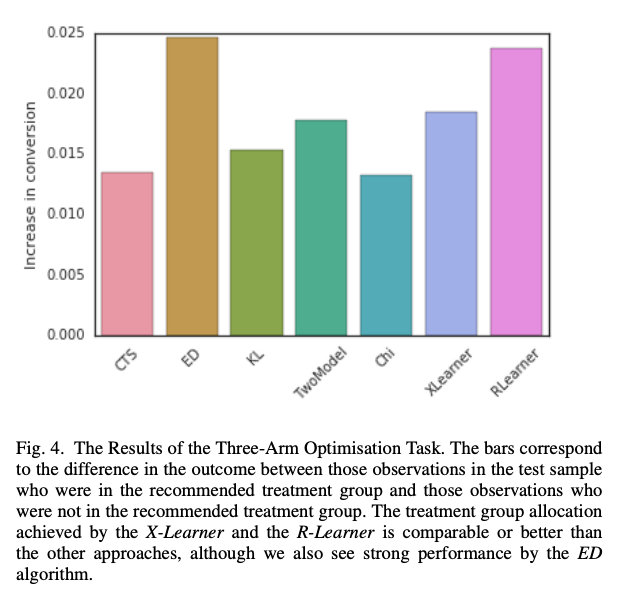
Finally, the authors confirm that the net Net Value CATE outperforms simple CATE by achieving higher net values across the board, which is not unexpected given Net Value CATE has exactly this optimisation goal.
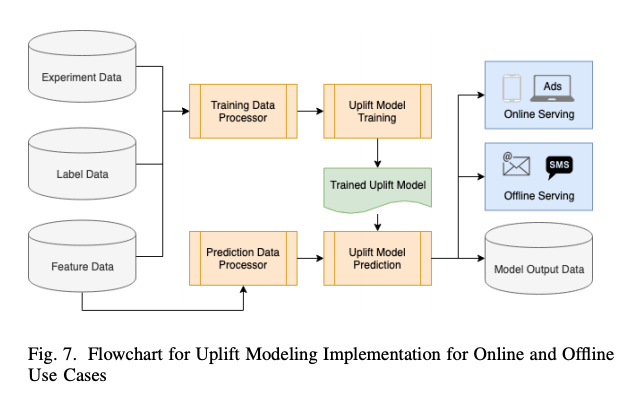
Causal Uplift Modeling – Platform Design
The final section of the paper outlines the system design of Uber’s uplift modelling platform. The system takes a target metric, features and configuration as inputs and generates user-level uplift scores for different treatments that can then be pushed to online services, offline services or a data store.

One thought on “Uplift Modeling for Multiple Treatments with Cost Optimization”